Defective computing: How algorithms use speech analysis to profile job candidates
Some companies and scientists present Affective Computing, the algorithmic analysis of personality traits also known as “artificial emotional intelligence”, as an important new development. But the methods that are used are often dubious and present serious risks for discrimination.
It was announced with some fanfare that Alexa and others would soon demonstrate breakthroughs in the field of emotion analysis. Much is written about affective computing, but products are far from market ready. For example, Amazon’s emotion assistant Dylan is said to be able to read human emotions just by listening to their voices. However, Dylan currently only exists in form of a patent.
So far, Amazon, Google et al. have not launched such products. Identifying unique signals that indicate that someone is sad seems to be a bit more complicated than they initially thought. Maybe someone’s voice sounds depressed because they are depressed, but maybe they are just tired or exhausted.
However, these difficulties do not prevent other companies from launching products that claim to have solved these complex problems by using voice and speech for character and personality analysis.
In Germany, two examples spring to mind. One is the company Precire, based in Aachen, a city on border with Belgium. Their idea: you record a voice sample, and based on the person’s choice of words, sentence structure and many other indicators, the software then produces an analysis of their character traits. The software can be used in staff recruitment or to identify candidates for promotion.
The company states that its software carries out the analysis based on a 15-minute language sample. The then CEO Mario Reis stated in an interview in 2016 that the results were based on science and scientifically tested. This statement is repeated in a book published in 2018. This book also cites additional studies and findings to further support the scientific grounding of the method.
Criticism of the method
Uwe Kanning, however, is sceptical. Kanning is a professor of business psychology and an expert in the field of recruitment. He criticises the scientific description: “As a whole, the book involuntarily highlights the deficits of the analytical insights into the software. None of the studies presented are independent of the vendor.”
Kanning further criticises that the documentation provided by the company leaves room for further questions - for example that the company analyses half a million characteristics. To him, this number appears to be inflated: “It is not clear what is measured, and the number can only be achieved by combining variables. For example, 50 variables could be graded on a scale from one to five, and every grade is referred to as a characteristic. By using such combinations, you get to this number.”
Above all, Kanning says that the software is based on a fallacy: “Precire uses the speech profiles of successful people in order to find a person with a similar speech profile. That is equivalent to a scenario where you have a very good salesman with shoe size 47 and therefore, in future, you will only employ people with that shoe size. The sample sizes are very small and there is the risk that randomly occurring characteristics are erroneously interpreted as causality.” In other words, it is wrong to assume that a certain shoe size is indicative of a certain characteristic or for high performance levels.
Companies that use Precires’s software can select the characteristics their applicants should have to be considered for a position. If a company uses characteristics based on their existing senior management staff – however they are measured – to create a profile for future managers, there is a real risk that only people with comparable characteristics are hired or promoted. Yet the company uses precisely these sorts of speech profile analyses of people in leadership positions to promote the company, and it even dedicates a whole chapter to it in the book mentioned above.
Even if leaders were to share similarities in speech patterns, the resulting personality profile is by no means a performance test. Business psychologist Kanning therefore generally doubts the use of such tests. “You can predict work performance based on such tests to a certain extent, but it ranges in low percentage values. By no means should such tests be the only selection tool. If you use them, they should be complimentary to a highly structured interview and a performance test.”
In addition, Kanning identifies further potential for discrimination as Precire does not state in its documentation how the software deals with dialects or accents. “How does the software deal with someone speaking in a strong Bavarian dialect, or someone speaking German with a strong accent compared to someone who speaks high German? Discrimination is practically inevitable.”
Improvements
Precire is familiar with these criticisms. Thomas Belker, Precire’s CEO, explains that the system is continuously improved upon. Voice analysis – pitch, fluctuations and similar – is not part of the psychological profile. Only the language used, such as choice of words and sentence structure among many other characteristics, is considered for analysis. On the subject of discrimination, Belker states that only speech samples where 80% of words can be transcribed are used. For example, if a person has a strong dialect or if there are long pauses, the software records an error, and the sample is not used.
In relation to the danger of discrimination, he emphasises that the software is only meant to be an additional support tool in the selection process and should not be the sole arbiter. “The decision is always made by a human”, Belker states.
In addition, the company is now working with a far larger sample size. An agency collected 16,0000 speech samples. “The agency has done everything possible to ensure that the sample demographically representative. We are satisfied with that they have succeeded in doing so,” explains Belker. He also says that discrimination based on demography could be excluded as this was explicitly tested for. The algorithm would not include age, sex or ethnic background in the creation of the profiles.
Nevertheless, questions remain: the personality tests underlying the software are not named. This lack of transparency prevents an independent scientific evaluation of their suitability.
The statement that the software does not discriminate also has to be further examined. The underlying research work on speech analysis goes in large parts back to pioneering work by the US Social Psychologist James Pennebaker. He found that there are clear differences in the choice of words depending on age and sex. Women appear to use “I” more frequently. In contrast, men use “the” more often. Younger people tend to use more auxiliary verbs, whereas older people use more prepositions. Does the algorithm consider the choice of these words? Precire uses a technique called machine learning, where it is not clear which factors the algorithm has used in its calculations, and how they are weighed. It is therefore not possible to exclude discrimination.
Word analysis without context
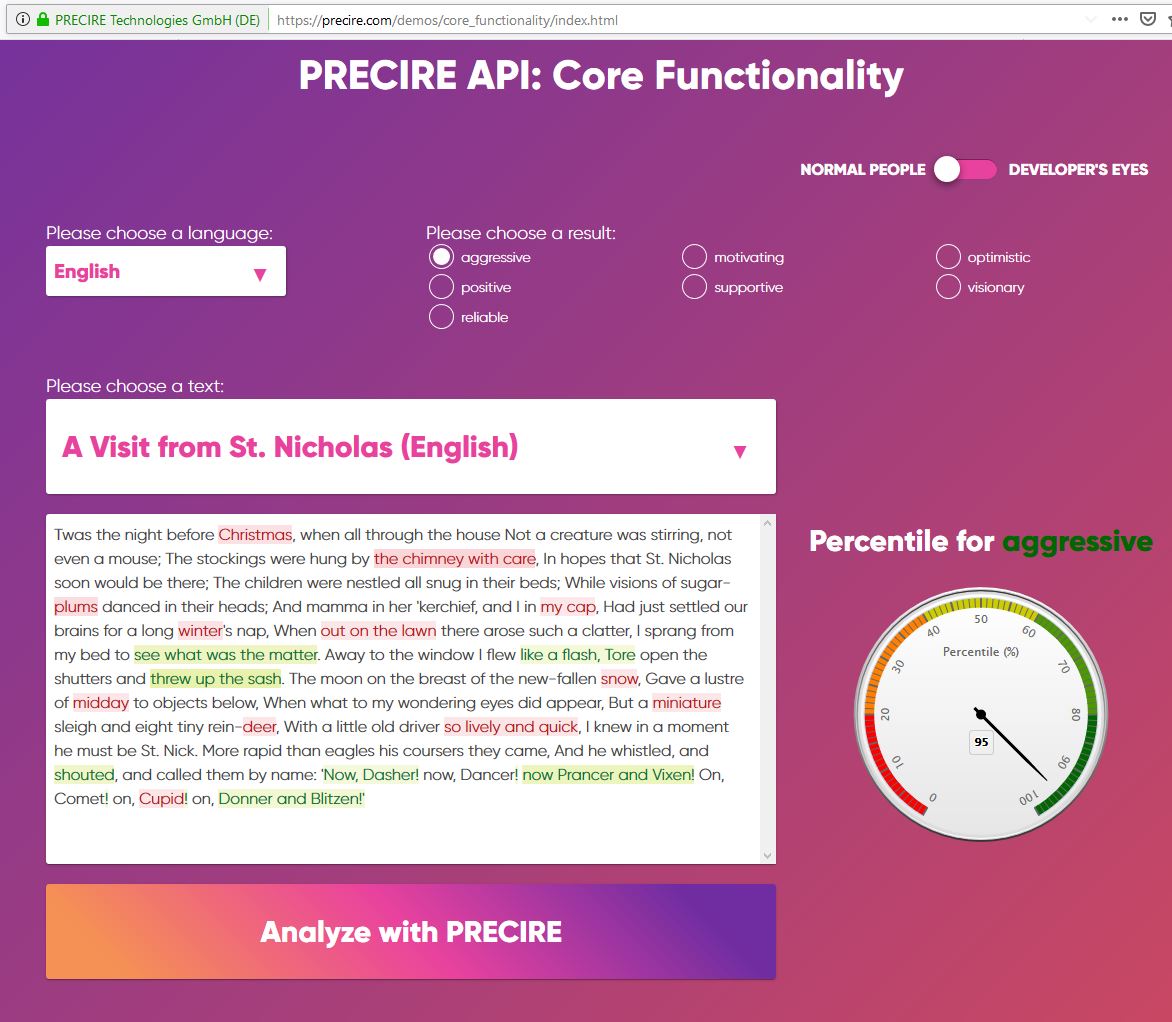
Precire states further that their algorithm is able to detect a person’s character outside of context, solely based on the speech sample. The content would be immaterial. “There are different levels of analyses. The communicative effect can be analysed independent of context, solely based on the words that are used”, explains Belker.
It isn’t exactly clear how this works. The company presents testing tools on its website to demonstrate the methods. But they fail to convince. A German text to advertise a Hackathon is made available, and users can analyse it based on characteristics such as “aggressive”, “positive”, optimistic” or “motivating”. The results are ambiguous: why is a phrase such as “see what was the matter” marked green when analysing for “aggressive” while “my cap” is red? How can characteristics be attributed to these phrases outside of context?
The company states that its website is being overhauled and that there would be more information about their methods in future.
But even if Precire has improved on its methodology, the question remains why the company launched its product with its original method. It is common practice in the age of agile project management to release products iteratively, but should such methods be used when they can influence people’s careers?
Randstad: Precire as conversation starter in interviews
Randstad is a satisfied customer of Precire. The company is a large recruitment agency. It uses the Software as a supporting tool. But checking qualifications, performance tests and a personal interview would still be far more important than the results of the speech analysis.
Andreas Bolder, responsible for internal HR management, thinks the analysis is a good conversation starter during the personal interview. It would help to “get to the point quicker”. Also, the low setup required is a bonus for both applicants and the company as it speeds up the selection process – two advantages marketed by Precire. Bolder could not say if the software really selected the better candidates or lowered staff turnover as there were too many factors in play. The same goes for diversity numbers: Randstad already had a very diverse staff before the introduction of Precire. The software may be contributing to it, but it would be impossible to prove if it further increases it.
100 Worte: Scientific breakthrough in psychological motive research or hot air?
Precire is not the only speech analysis system for recruitment. The company 100 Worte (100 Words) also promotes algorithmic speech analysis to support candidate selection. According to its website, the company uses an algorithm that can create personality profiles by analysing cover letters. It scans texts for certain signal words that assign certain motives to applicants, for example a power motive or an affiliation motive.
Motive research is a well-established branch of psychology that can contribute to assessing a person’s suitability for a position. It posits that people have different inherent motives that guide their actions and choices. Using a relatively elaborate setup, analysts can decide if for example someone prefers to lead or if someone prefers to work by themselves. A person with a power motive enjoys influencing others, does not shy away from making unpopular decisions, and generally likes to take on responsibility. People with an affiliation motive greatly enjoy socialising, and they like to make friends. Such motives are not exclusive to one another and people often have several motives that guide their actions. Used correctly, the method can produce meaningful and helpful results.
The common scientific method to measure motives is complex: normally, candidates are asked to write stories based on pictures that relate remotely to the motive to be measured (picture story exercises), for example to power, or to management. These stories are then coded for the relevant motive signals and compared to stories based on the same pictures written by people who have been stimulated for the same motive (like a thermometer). For example, test subjects were part of a role play in which they had a powerful position. People who performed well in these role plays are assigned a higher power motive than those who performed poorly. The process is laborious and time consuming, as people have to code the stories manually to include the context in the analysis.
An expert in this field is Oliver Schultheiss, professor of psychology at the University of Erlangen, and director of the human motivation and affective neuroscience lab. In 2013, he investigated whether the complex coding process could be automated. The study explored if it was sufficient to look for certain signal words instead of analysing sentences in the context of a story. The result: there was a certain correlation between the automated and the human coding, but it was not good enough to use it.
Schultheiss provided his data to 100 Worte, but he was not involved their software development. The company fed the data to its algorithms and says it produced better results than Schultheiss. To them, this proves that signal words do work – but Professor Schultheiss contradicts this: “100 Worte ran its model on our data and concluded that their model is good at detecting signal words. However, they ran the analysis on a copy of a copy, and that is not how it works. Their algorithm should have been tested independently – firstly, standardising their tool by stimulating test persons for certain motives and then comparing the results with non-stimulated test subjects to see if their word-model can distinguish the first from the second group. They have not done this. “
Business psychologist Kanning furthermore states that job applications often are not suitable for analysis, as standard templates are frequently downloaded from the internet nowadays. Therefore, the algorithm does not analyse the person who applies for a job, but the person who created the template cover letter.
Moving too fast?
The CEO of 100 Worte, Simon Tschürtz, concedes that the company is reducing its reliance on application letters and is returning to picture based stories. He, too, emphasises that the tool is only meant to support recruitment and should never be used as sole decision making tool.
However, he vehemently rejects Schultheiss’ criticism. The company deliberately did not create its own dataset to ensure that the data was truly independent.
In addition, Daniel Spitzer, co-founder and chief product officer at 100 Worte states that the company’s algorithm can now detect context – an important step forwards in comparison to the 2013 study. “The text analysis that we developed is far more elaborate than the one used by Professor Schultheiss.” Their algorithm would achieve higher rates than human coders. A publication on this topic is in preparation and will be published soon.
If 100 Worte can prove this statement, it would represent a real break-through in the area of motive research. However, there are reasons to be sceptical: according to Schultheiss, the work of an academic research group dedicated to this subject has so far not produced satisfactory results. The question of whether a machine will ever be able or even better than humans in story coding is still left unanswered.
Similarly to Precire, the company also has to contend with the question whether they should have gone to market with an immature product.
Questionable use of personality tests
Independent of the significance of the results produced by Precire or 100 Worte, there are fundamental criticisms of personality testing in HR. The Organisation Analysis & Policy Observatory (APO) writes in a report on automated candidate selection:
“Inferred traits may not actually have any causal relationship with performance, and at worst, could be entirely circumstantial.”
The organisation lists further points of criticism that question the use of personality testing for candidate selection:
- Personality tests are often tested on university students. This puts their transferability onto the general population in doubt.
- Personality tests are always developed in the context of historical and social patterns. People who do not fit these standard patterns – based on cultural differences, their sex, or for other reasons – may act and react differently, even though they have the same capabilities
- The tests are rarely validated; this means that usually it was not checked if a test for a certain job measures what it should measure, or whether the test results in any way allow for conclusions to be drawn about the suitability of a person for a job.
The organisation refers to the apps Koru and Pymetrics which use personality testing to indicate how well an applicant fits an open position, but these points of criticism are equally valid for Precire and 100 Worte.
This generally limits the use of personality testing software.
Potential for Automation
HR recruitment expert Kanning does see the potential for computer supported selection, but only in larger companies – only these will be able to generate sufficient data to identify which qualities in a company make people good leaders.
The scenario would be as follows: staffs’ leadership abilities would have to be tested in an assessment centre. They would then receive targeted support to help them develop certain skills, such as organisational management or emotion control – say, someone who is impatient or quick tempered would get training to learn to remain calm. HR departments could collate this data about their employees who go on to become managers. Building on that, it would be possible to check if there are certain correlations between personality traits and an indicator of success, such as customer satisfaction, turnover, or staff satisfaction. Such an analysis would be time-consuming and it is questionable if it is worth the effort.
The advantage would be, however, that the data is context-specific and that the models could be continuously improved and renewed. The company could also include diversity aspects into their model to avoid that only people similar to each other are promoted or hired.
The apps mentioned by the Analysis and Policy Observatory do not fulfil these standards, and Precire also appears to use a standard model that is not validated for specific contexts.
To generate a universally applicable dataset that covers all industries and job profiles and that can then be adapted to the specific context of a company would present developers with a formidable challenge: the dataset would have to capture character traits of people who are successful in their jobs, independent of their profession or the industry they are working in. This would have to include the character traits of a telco service adviser as well as the manager of a private bank – the database would be huge. And how would one go about collecting this data? Which company can legally do so and would willingly hand it over? What indicators should be captured? It requires more than an HR manager describing their ideal person, as this would lead to bias. For an algorithm to learn what happens in reality, the character traits and performance data of hundreds of thousands of people would have to be collected. Only then would it be technically possible to detect valid patterns that make a good manager or a good service adviser.
As no company has achieved this yet – and it may well be a question of time – current products rely on standard models that present general pass criteria for job offers. It should be obvious that this is too simple a model.
Success (and hype) continue
Other recruitment systems also make claims that are scientifically unfounded. This does not prevent companies to further fuel the hype. Other than text and speech, companies also analyse facial expressions and gestures: the company HireVue claims that their software can draw conclusions about a person’s working style based on their posture, gestures and facial expressions. This is despite the fact that especially the analysis of facial expressions to detect emotion has recently been heavily criticised.
When using Precire and 100 Worte to pre-select candidates, there is a good chance that people are excluded who would be perfectly suitable for the job. Without a more detailed description of methods and better validation of the results, it is not clear whether or not their algorithms discriminate or not. In motive research, for example, it is easy to detect the sex of a person. Professor Schultheiss therefore issues a warning: “As long as the companies do not show how their software works and demonstrate that their results really are independent, and exclude sexism, ageism, and racism, I would be doubtful of their claims. I would only trust companies that show their data. These studies have to be published and others have to be able to critically appraise them. Everything else is just a claim.”
The criticism of their methods and the only partial publication of their approach have not put a stop to Precire’s success – not even the fact that they have been awarded the Big Brother Award 2019, as the use of their software in call centres allegedly contravenes data protection regulation. The company has many prominent clients, it lists Frankfurt Airport, KMPG and the German insurer HDI on its website. The extent to which these companies have scrutinised the methods or if the software is used to measure their staff’s performance is unknown.
Edited on 4 November 2019 to provide a more accurate description of the training method of the company 100 Worte.
Did you like this story?
Every two weeks, our newsletter Automated Society delves into the unreported ways automated systems affect society and the world around you. Subscribe now to receive the next issue in your inbox!